


谐云作为国内企业级Paas服务商领头羊
以“底层核心技术+超前发展理念”
致力于为企业数字化转型提供最佳解决方案

5月17-18日,为期两天的AI+研发数字(AiDD)峰会在上海完满收官!峰会吸引了近千位来自金融、通信、泛互、消费电子、企服等行业的技术从业者参会,现场学习氛围热烈。
谐云技术总监王羽中受邀出席AI算力与优化分论坛,聚焦如何构建云原生算力基础设施、大模型创新、算法突破等内容,作《构建云原生算力基础设施,驱动大模型创新实践》的精彩演讲。以下为王羽中峰会演讲实录。
🌟 关注公众号,留言“云原生算力”或“AiDD”,即可获取演讲PPT及试用

01
算力基础设施与大模型
自2022年11月30日ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。大模型因其拥有表达能力好、泛化能力好、能够处理复杂任务和语义理解、知识库存储容量大等优势很快迎来了迅猛发展。大模型将重新塑造人类知识应用、创造和转化的模式,在经济社会发展中产生巨大价值。
统计数据显示,在大模型落地应用中,45%的企业处于观望阶段、39%的企业处于探索可研阶段、16%的企业处于试点应用阶段,而全面落地应用的企业为零。
大模型落地难的原因在于大模型幻觉、答案时效性与数据质量问题。以大模型幻觉为例,现阶段大模型输出准确度能够达到70%-90%左右,由于对准确性、可控性要求较高,大模型面客应用都暂时无法落地,应用将以对内为主。
目前,在大模型数量上我国已经和美国逐年持平,但在模型的效果上依旧存在较大的差距。国外以GPT-4为代表的大模型参数规模已经达到了1.8万亿,国内以文心一言4.0为代表的大模型参数规模尚未突破万亿规模的参数,参数规模是影响模型效果的重要因素之一。
算力对大模型的重要性
作为大模型的基础“底座”,算力在其中发挥着关键的作用,动辄百亿甚至千亿数据规模的大模型训练。
算力规模决定大模型参数规模,从而间接决定大模型的效果和落地实践的可行性。如何解决大模型落地进程慢,缩短国内大模型与国外大模型性能差距,算力作为大模型的基础设施都起着决定性作用。
要实现大模型的弯道超车,要实现大模型的全面落地实践,算力基础设施建设是重中之重。
算力基础设施建设
围绕加快算力基础设施建设应用,我国近年来出台一系列重要政策举措,实施一大批重大工程项目。截至目前,从计算设备侧看,我国近六年累计出货超过2091万台通用服务器,82万台AI服务器,算力总规模达到302EFlops,全球占比33%,增速达50%,其中智能算力保持稳定高速增长,增速达72%。
算力基础设施建设进程加快,如何建设高效、灵活、稳定的算力管理平台,向下实现算力资源的统一纳管,向上为大模型提供算力服务,成为加速大模型落地实践的关键。
02
面向大模型的云原生算力基础设施关键要素
支持异构算力调度
《中国算力白皮书(2022)》和中国信通院的数据,2021年第四季度,英特尔占据了全球84%的CPU算力芯片市场份额和71%的FPGA算力芯片市场份额,英伟达占据了全球95.7%的GPU算力芯片市场份额。
近年来,我国国产芯片自给率不断提升,2019年为30%《中国制造2025》计划要求在2025年,国产芯片自给率要达到70%以上。
未来的算力中心必定是存量的英伟达GPU和国产的AI芯片共存的模式,因此算力管理平台必须能统一纳管英伟达GPU和国产AI芯片等各种异构算力资源,实现算力的统一分配和调度。
支持跨算力中心调度
算力管理平台需要支撑跨算力集群和算力中心的算力管理和调度;有效整合分散在各个算力中心的算力资源,聚少成多,为大模型的训练提高算力支撑。
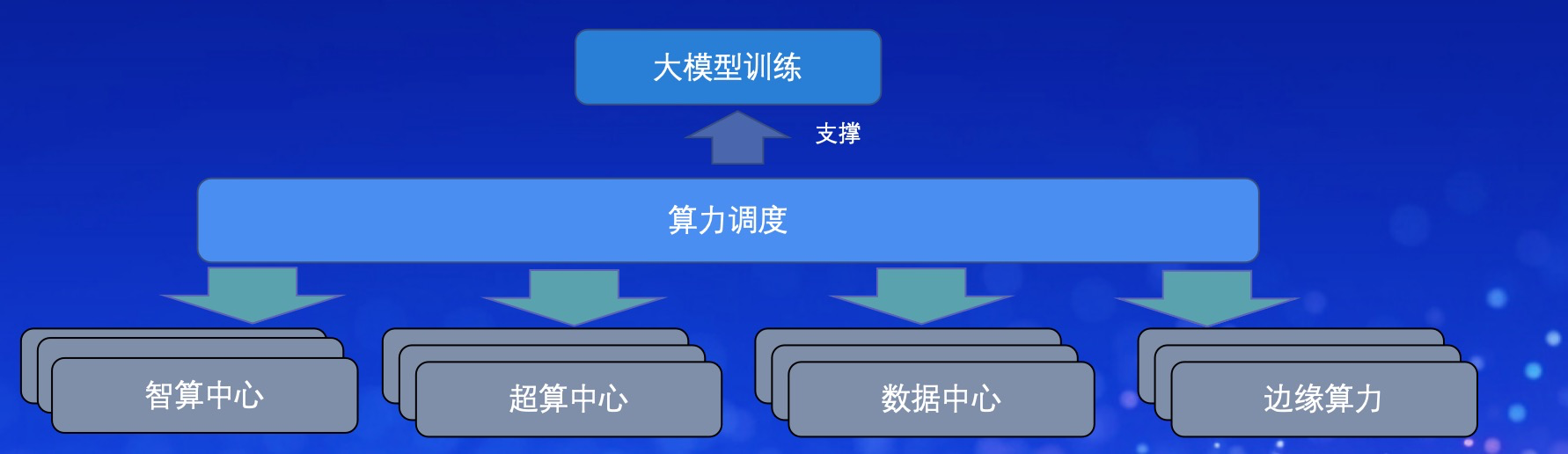
支持多种类型任务调度
大模型和小模型的结合将成为未来AI产品的重要发展趋势,也是人工智能应用赋能行业发展的重要方向。
大模型的优势在于拥有更多的参数,能够更准确地捕捉数据中的模式和特征,处理复杂任务的表现更好,能够实现更准确、自然的内容输出等。
小模型的优势在于参数量较少,因此训练和推理速度更快,且占用资源少,能够在资源受限的设备上运行等。
支持算力精细化调度
算力管理平台对任务的精细化调度包括算力聚合和单卡共享、算力超分和优先级调度、算力动态分配和调度。
实现算力资源利用率的有效提升,要发挥算力资源的最大价值,实现降本增效。
以上为模块部分内容,可留言“AiDD”获取完整PPT
03
面向大模型的云原生算力基础设施技术方案
云原生是建设算力管理平台的最佳方案。
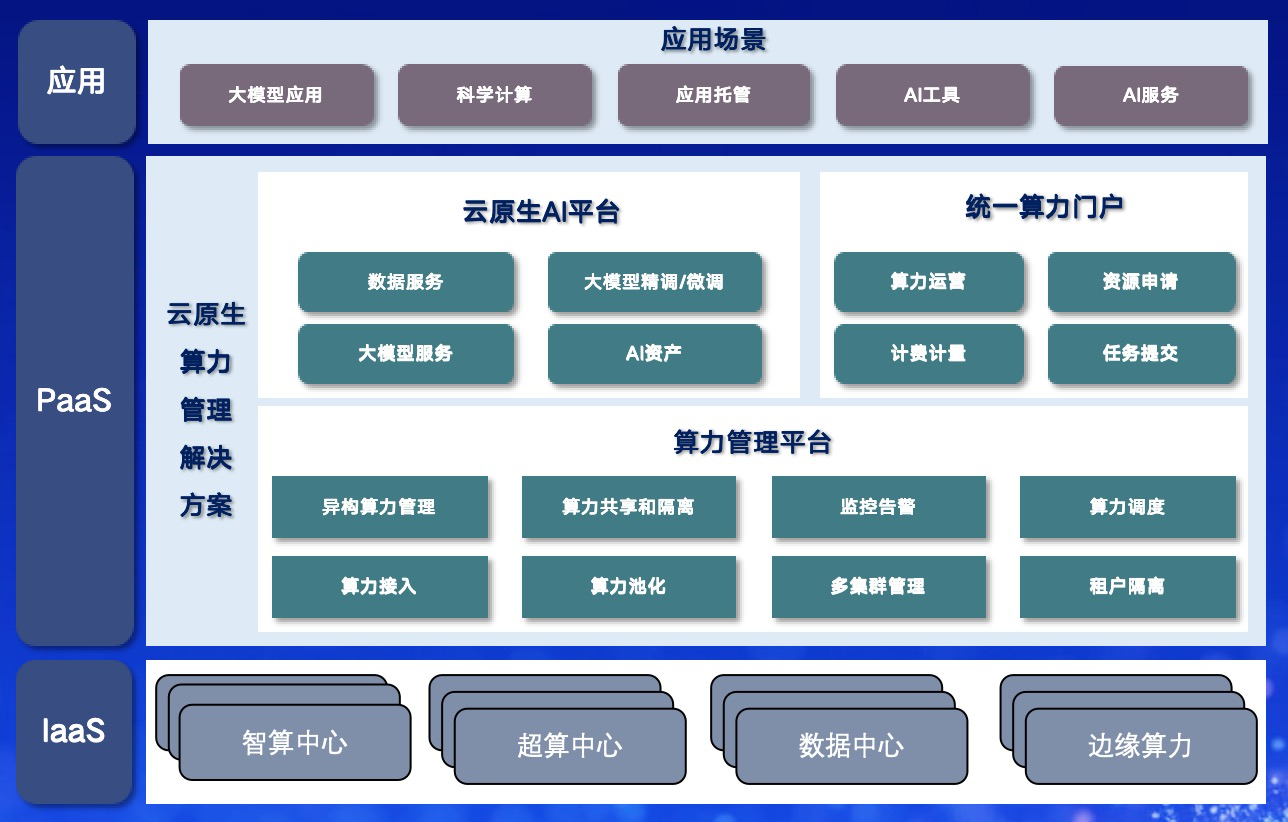
平台架构
统一算力门户
基于算力管理底座提供算力资源申请、运行、监控等管理全流程
云原生AI平台
针对大模型精调/微调、大模型服务等场景,构建云原生AI平台,整合分布式训练、服务部署、数据服务等能力,提高大模型开发部署效率
算力管理平台
针对智算算力、HPC算力、边缘算力等算力资源,非侵入式接入异构资源,通过按需分配、精细化管理与调度,为大模型应用、算力运营等提供算力底座支撑
关键技术点1-跨算力中心的纳管和调度
云原生算力管理平台上层控制集群中引入自研调度器,实现将用户提交的任务调度到对应的算力集群中运行,支持优先级调度、价格最低调度等多种调度策略。同时,Proxy和Manager一一对应,实现任务的下发和底层算力集群的状态、资源、任务状态等上报。
关键技术点2-异构资源纳管和调度
以云原生技术为核心实现对多种异构资源的统一管理与调度。包括基于Volcano的高性能工作负载调度引擎实现AI、高性能计算等批量计算任务调度和编排管理和调度。
关键技术点3-算力超分和优先级调度
支持资源超分,所有队列申请资源总和可大于集群实际资源总和;
基于任务的资源实际使用情况和资源预测,动态计算和调整高低队列资源大小;
当高优先级队列提交的任务没有足够资源运行时,可以驱逐和抢占低优先级队列资源;
构建干扰检测模型实时监测高优先级任务是否受到干扰,高优先级任务受到干扰时,可以压制和驱逐低优先级任务;
本节内容还包括算力资源共享和隔离、算力资源动态共享、多卡共享、精细化计费计量、云原生AI平台等关键技术点。可关注公众号,留言“AiDD”获取完整内容。
04
典型案例
高校计算中心-异构资源管理平台
某高校面向校内和校外的科研需求建设一个国内领先的算力中心,谐云为该高校计算中心打造的异构资源管理平台,统一管理高校自有算力中心与来自各类运营商、云厂商等提供的算力资源,实现资源一站式管理与运营,提升用户体验。
政府联合谐云建设一体化MLP平台
某政府针对算力资源、数据、行业算法模型等资源分散、无法高效利用等问题,联合谐云建设一体化MLP平台。
实现对全市异构的、分散的算力进行统一纳管,并对外为用户提供算力服务;
提供大模型、小模型等全链路服务,从数据标注-模型构建-模型训练-模型服务-服务应用的端到端服务;
提供将数据、模型、算法等进行共享,提高资源复用能力;
以上此次峰会演讲的部分内容,可留言“AiDD”获取完整PPT







