



浙江大学DeepSeek系列公开课第一季的主题是解码Deepseek“破圈”之力探索人工智能技术明日世界,其重心是在“技术”两个字上。浙江大学邀请了八位老师,通过通俗、科普、生动的语言,从不同的维度对技术要点进行了深入浅出的讲解。但是,单单普及技术是不够的。人工智能的一个重要的特点就是应用场景多样新。
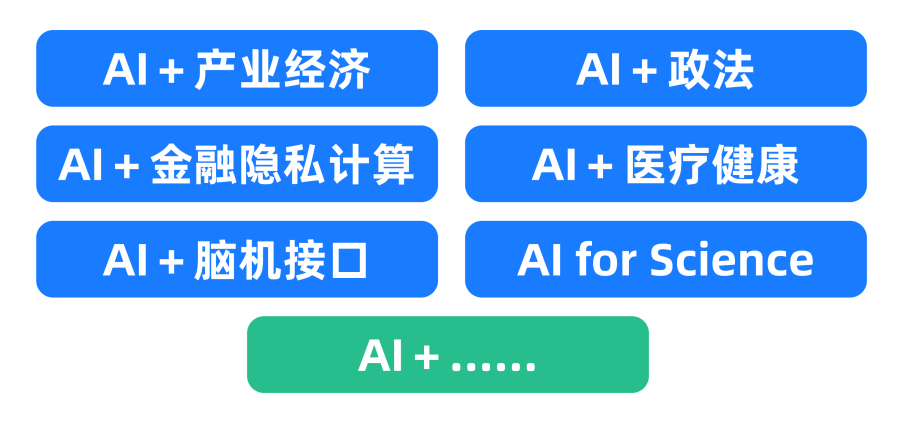
而系列公开课的第二季将视角转向如何用技术解决现实场景下的具体问题,讲述人工智能的渗透与再生,探索大模型生态下AI+X产业新触角。
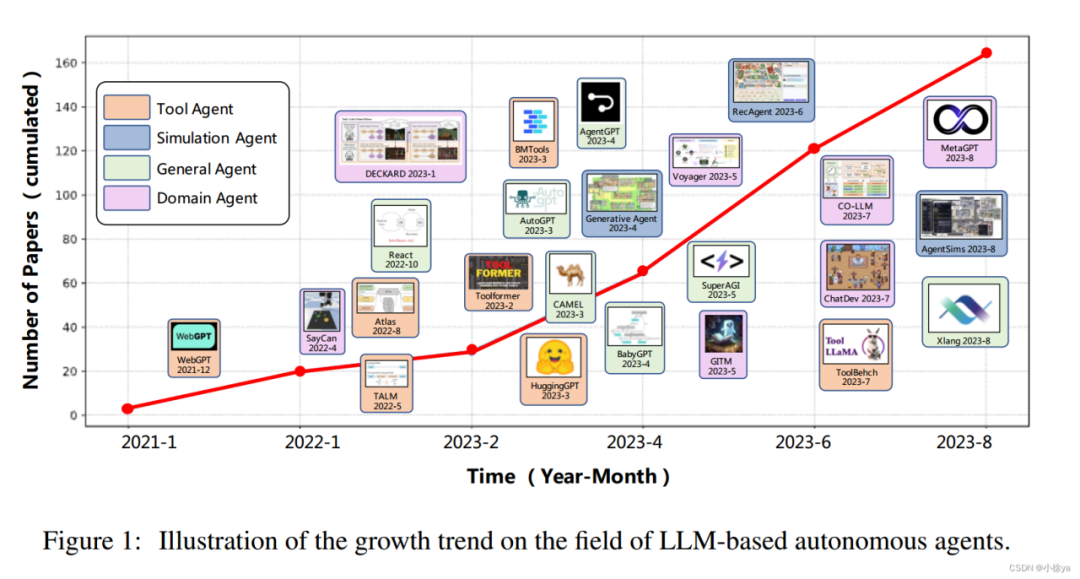
公开课01
从大模型、智能体到复杂AI应用系统的构建——以产业大脑为例
报告嘉宾:肖俊
浙江大学计算机科学与技术学院教授,博导,人工智能研究所副所长、人工智能教育教学研究中心副主任课程摘要:2024年下半年以来,以DeepSeek-R1和GPT-o系列为代表的新一代大模型能力得到大幅提升并有望进入大规模产业转化阶段,本次课程将首先探索新一代推理大模型之所以强大的原因,进一步结合当下受到广泛关注的智能体(AI Agent)工具讨论构建复杂AI应用系统的途径,最后分享四链融合产业大脑这一复杂AI应用系统案例并展望未来AI系统研发的范式。
01
大模型推理能力快速提升
快速回望历史--大模型的产生
大模型发展迅速,参数量从百亿到万亿规模。大模型能力不断涌现,在包括知识问答、数学、编程等能力上达到新的高度,多种任务上的表现超过人类水平。然而早期大模型在推理能力上存在明显短板。
大语言模型易产生幻觉,在数学推理方面表现在推理能力严重不足体现在简单数值比较错误、多步推理能力弱、推理不一致等。Yann LeCun的批判观点:对纯粹扩大规模方法的根本质疑Mehrdad Farajtabar:"LLM本质上是统计模式匹配工具,而非真正的推理系统"、"下一个词预测框架不足以产生真正的理解"
而2023-2024年OpenAIo1/03、DeepSeek-R1的出现,标志着大模型推理能力取得突破性进展。OpenAIo1/o3在数学和代码推理任务上的卓越表现开源大模型DeepSeek-R1在MATH基准上达到87.2%的准确率。

这种深度推理能力是如何实现的?是单纯的规模扩展结果,还是有其他关键因素?
02
推理模型和思维链
推理大模型:通过测试时拓展(Test-Time Scaling)、强化学习、蒸馏等技术,大模型的推理能力不断增强。
OpenAI-o系列推理模型:o1/o3 在回答问题之前先Reasoning,生成一个详细的内部思维链,拟人类的深思熟虑,逐步分解复杂的问题,提高答案的准确性和深度。

然而让AI实现这种类似于人的推理过程需要巨大的样本数据和算力支持。那么如何低成本实现推理模型?

图片来源:LIMO: Less is More for Reasoning
s1通过在一个精心构建的小规模数据集上(1000条数据)进行微调并结合预算强制技术,实现了强大的推理能力和测试时计算扩展性。
LIMO通过817个训练样本(题目难度高,覆盖知识面广,解题步骤精细),模型就能在复杂的数学推理任务中取得有益的表现。
03
智能体(AI Agent) 是什么?
(用大模型写邮件)
如果你只有一个大模型,使用它回复邮件的过程大致如下:
1. 用户打开邮箱,手动拷贝邮件内容
2.用户将邮件内容拷贝到大模型运行界面的对话框,写提示词:请基于以下邮件内容帮我草拟一封回复
3.大模型根据提示词自动生成回复邮件(只有这个步骤是大模型自动完成,其余步骤均需要用户自行手动操作)
4.用户将大模型生成的回复邮件拷贝至邮箱
5.用户填写地址、邮件标题,点击发送
大语言模型(LLM )可以接受输入,可以分析&推理、规划任务、输出文字\代码\媒体。然而,其无法像人类一样,拥有运用各种工具与物理世界互动,以及拥有人类的记忆能力。
LLM:接受输入、思考、规划任务、输出
人类:LLM(接受输入、思考、规划任务、输出)+记忆+工具
智能体(AI Agent)是大模型(Brain)的眼(Observation)和手(Tools)

一个具体的例子:
撰写调研报告:调研特斯拉 FSD 和华为 ADS 这两个自动驾驶系统
调研员智能体,从网络进行搜索并总结报告。通过LLM提示工程(PromptEngineering),让LLM以调研员的角色去规划和拆分任务,使用提供的工具,完成调研过程,生成调研报告。在定义角色时,会为其注册下面列出的各项工具。
第一步:智能体进行任务拆解,首先调用CollectLinks工具从搜索引擎进行搜索并获取Url地址列表
第二步:调用WebBrowseAndSummarize工具浏览网页并总结网页内容(此工具调用了LLM)
第三步:调用ConductResearch工具生成调研报告(此工具调用了LLM)
智能体帮助人在大脑(LLM)、工具、感知(传感器)之间搭建桥梁。智能体的研究和发展也越来越受到研究者和企业的关注。甚至已经出现了智能体的概念框架模型。
Models,也就是我们熟悉的调用大模型API。
Prompt Templates,在提示词中引入变量以适应用户输入的提示模版。
Chains,对模型的链式调用以上一个输出为下一个输入的一部分。
Agent,能自主执行链式调用以及访问外部工具。
Multi-Agent,多个Agent共享一部分记忆,自主分工相互协作。
更复杂的任务:大小模型协作的生成式智能体。工作流程: 大语言模型负责规划和决策,AI小模型负责任务执行
ChatGPT: 具有强大的任务规划和工具调用能力
Hugging Face: 最大的AI模型社区,每个模型都有详细的功能描述
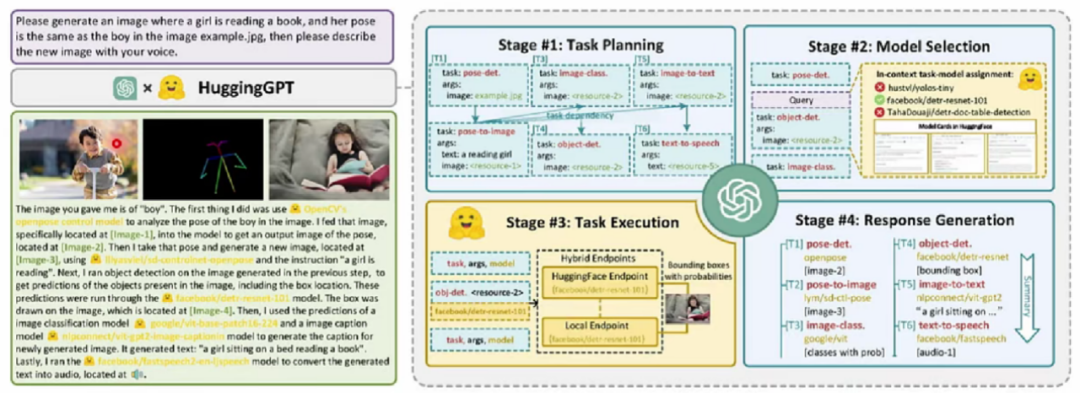
举例:请生成一个女孩正在读书的图像,她的姿势与图像example.jpg中的男孩相同,然后用你的声音描述这个新图像。请生成一个女孩正在读书的图像,她的姿势与图像example.jpg中的男孩相同,然后用你的声音描述这个新图像。
任务规划(四个阶段)-寻找调用最适合的工具(姿态检测/图像生成)-串联工作流程-完成复杂任务
大语言模型正在成为人工智能时代的信息系统入口。安卓/OS这样真正的操作系统--能够为用户提供信息系统入口/界面,同时智能时代一直没有出现像Windows、可以管理计算资源并支撑应用开发。而大语言模型,正在起到信息系统入口界面作用。
公开课02
DeepSeek技术溯源及前沿探索
报告嘉宾:朱强
浙江大学计算机科学与技术学院教授,博导,国家百千万人才工程入选者,浙江省特聘专家,浙江大学“求是工程岗”获得者,中国人工智能学会人机融合智能专委会副主任委员,人工智能省部共建协同创新中心(浙江大学)科研与校企合作主管。
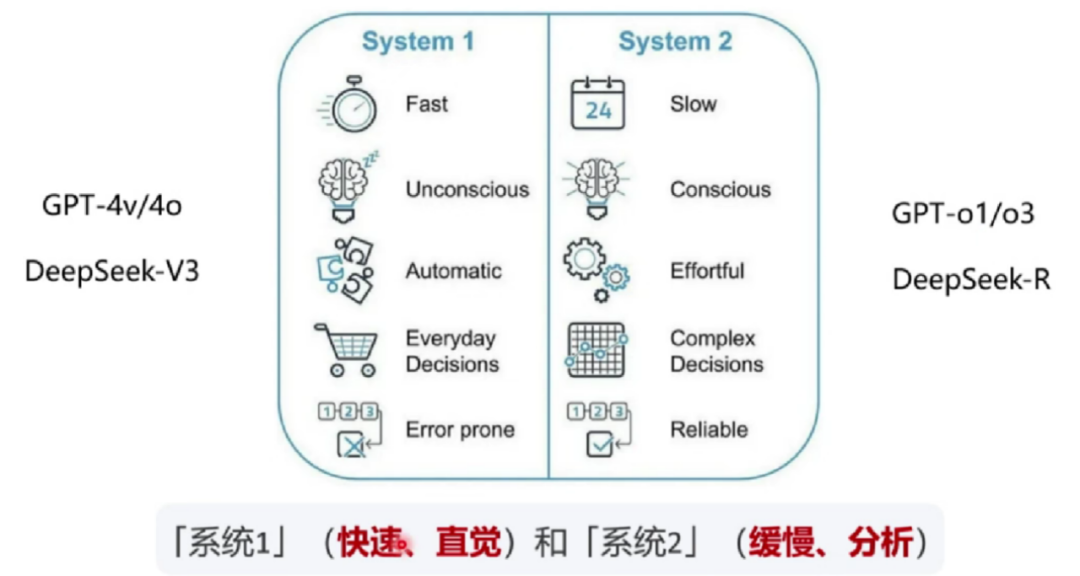
朱强教授从技术脉络出发,探讨DeepSeek的起源和演化。语言模型以理解和生成语言为核心,经历了从传统统计方法到以Transformer为基础的演变,后者通过自注意力机制革新了语言建模。而ChatGPT通过大规模预训练与人类反馈对齐,推动生成式AI走向实用。如今,DeepSeek引领了一波新热潮,通过大规模强化学习模拟类人推理和决策过程,极大地推动了从生成大模型【系统1】到推理大模型【系统2】的转变,为新一代智能体提供了技术支撑。这些技术演变不仅推动了未来产业的智能化升级,也将深刻影响人机交互、创新应用和社会结构。
01
语言模型
语言模型终极目标:对于任意的词序列,计算出这个序列是一句话的概率。用通俗的语言讲,就是当模型生成一句话时,这句话是不是一句“人话”
语言模型基本任务:让计算机理解人类语言。编码-让计算机理解人类语言;Word Embedding-用一个低维的词向量表示一个词能使距离相近的向量对应的物体有相近的含义。
下面这个例子中通过四句话的完形填空推理推测“tezgüino”一词的真实含义。
“有一杯tezgüino在桌上”
“每个人都爱tezgüino”
“tezgüino会让你喝醉”
“tezgüino是玉米做的”
推测tezgüino是一款用玉米制作的酒类名称。
而这种推理成为了训练大语言模型的基础。

02
Transformer
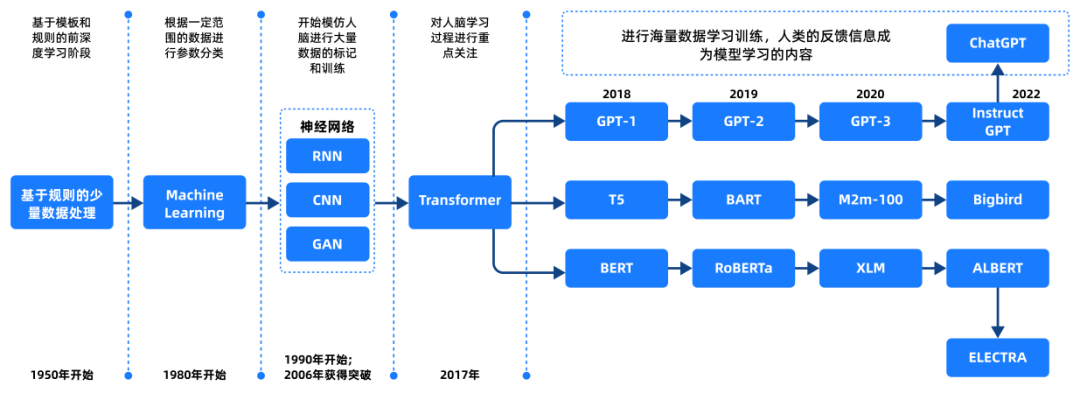
语言模型的技术演化:基于统计的N-gram(1970后);基于神经网络的LSTM/GRU(2000 后);Transformer (2017 后)。
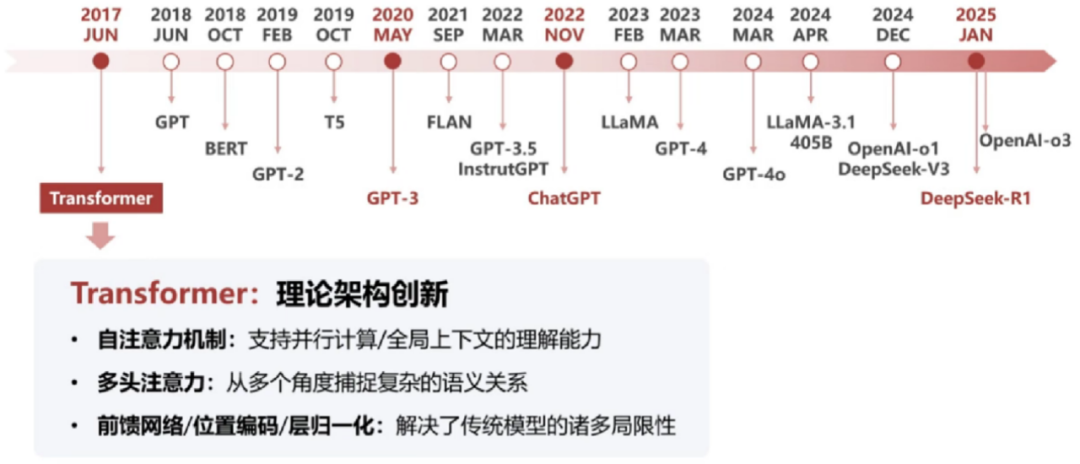
Transformer:大模型的技术基座
谷歌团队2017年发表《Attention Is All You Need》引入全新注意力机制,改变了深度学习模型的处理方式。
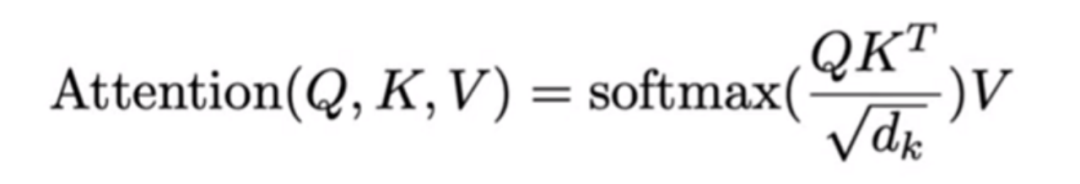
Transformer:(自)注意力机制
在理解语言任务时,Attention 机制本质上是捕捉单词间的关系。下面的例子展现这种单词关系之间的捕捉eating和green是低注意力关系,而eating和apple/green和apple是高注意力关系。
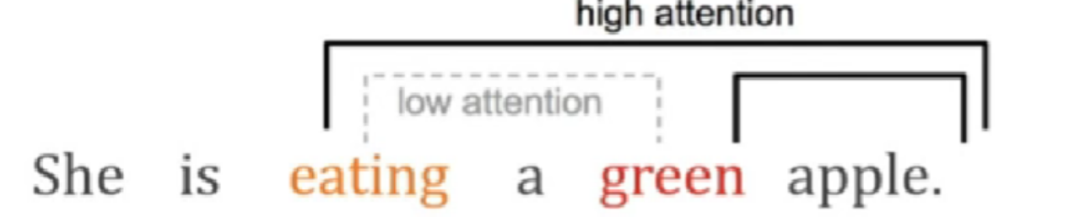
在理解图像任务时,Attention机制本质上是一种图像特征抽取。
Transformer:训练机制
场景:
你在图书馆想找一本关于“机器学习基础”的书
Query:描述要找的书(精准的需求描述)
Key:书的索引编号(高效的书籍定位)
Value:内容的抽取(由目标任务驱动)
每个学生去寻找一本书的过程其实就是在不断地优化图书馆查书这个系统。

自监督学习
语言:Masked Langauge Modeling(MLM)模型会不断地在句子中'挖去一个单词,根据剩下单词的上下文来填空,即预测最合适的'填空词’出现的概率,这一过程为'自监督学习。
图形:通过随机遮盖部分输入数据(如图像)并重建缺失内容,让模型从上下文中学到图像的深层特征,常用于计算机视觉任务。
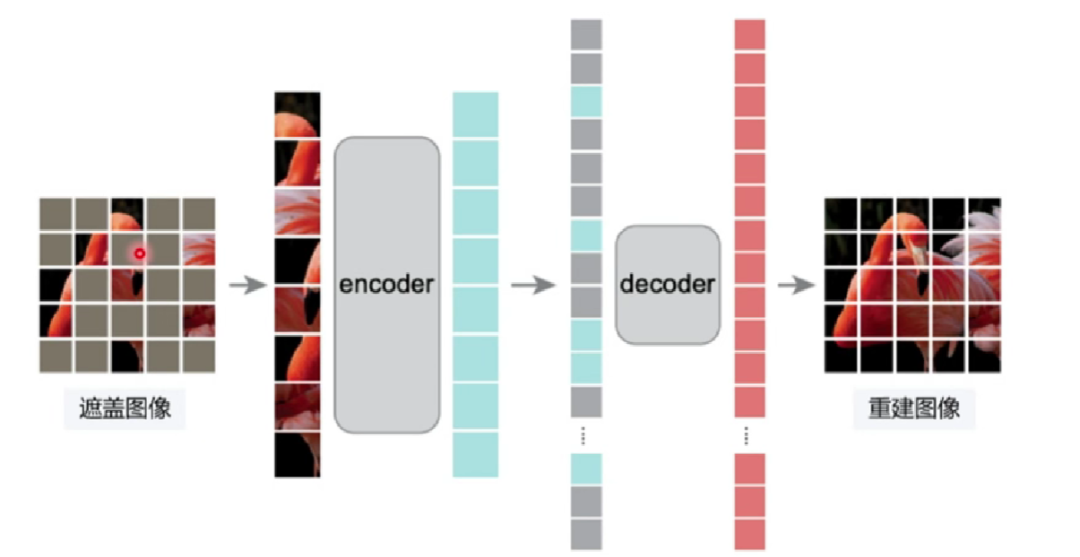
训练 transformer 的通用之力
数据是燃料、模型是引擎、算力是加速器。
数据:训练中使用了45TB数据、近1万亿个单词(约1351万本牛津词典所包含单词数量)以及数十亿行源代码。
模型:包含了1750亿参数,将这些参数全部打印在A4纸张上,一张一张叠加后,叠加高度将超过上海中心大厦632米高度
算力: ChatGPT的训练门槛是1万张英伟达V100芯片、约10亿人民币。
大数据、大模型、大算力下以“共生则关联”原则实现了统计关联关系的挖掘。
大模型脉络:

03
ChatGPT
GPT-3:语言模型的转折点
大语言模型:1750亿参数
涌现能力:随着模型规模增大而出现的新能力
生成/创造:Artificial Intelligence(人工=>艺术)
ChatGPT:人工智能的IPHONE时刻--人工智能从阳春白雪走到了群众当中。
OpenAI技术白皮书:
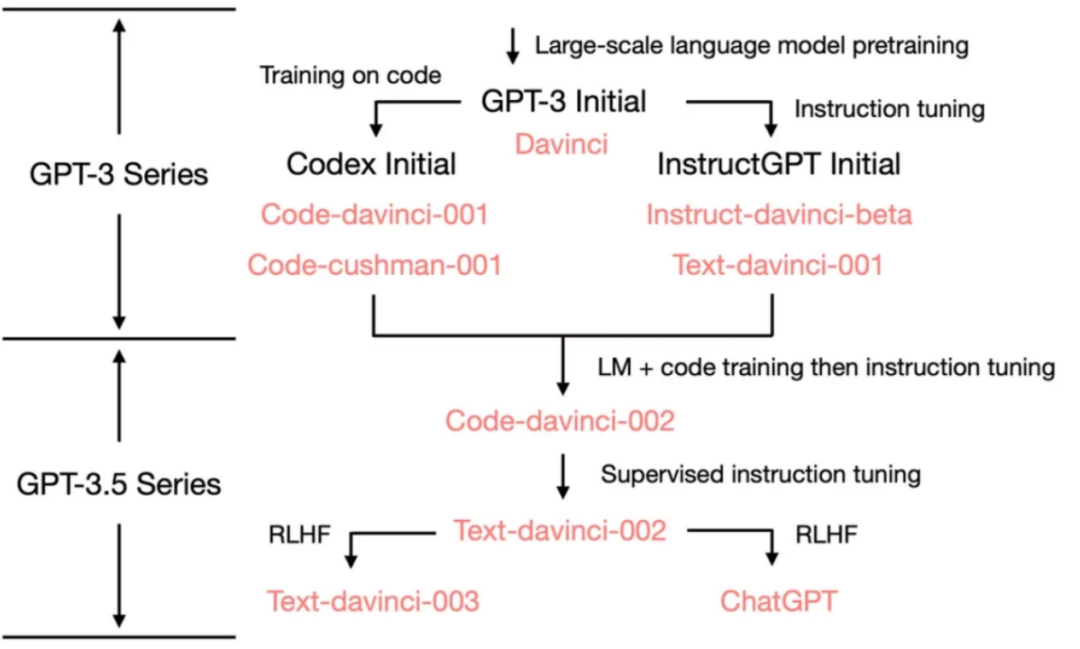
GPT-3 Initial
初代 GPT-3 展示了三个重要能力(来自于大规模的预训练)。
l 语言生成:来自语言建模的训练目标(说人话)
l 世界知识:来自 3000 亿单词的训练语料库(百晓生)
l 上下文学习:上下文学习可以泛化,仍然难以溯源(触类旁通)
初代 GPT-3 表面看起来很弱,但有非常强的潜力,展示出极为强大的“涌现”能力。
技术路径
GPT出现后的两条技术路线:Codex Initial / InstructGPT Initial。
2020-2021年,OpenA1投入了大量的精力通过代码训练和指令微调来增强 GPT-3。
使用思维链进行复杂推理的能力很可能是代码训练的一个神奇副产物。
使用指令微调将 GPT-3.5 的分化到不同的技能树(数学家/程序员/...)。
Code-davinci-002
1)指令微调不会为模型注入新的能力(解锁能力)
2)指令微调牺牲性能换取与人类对齐(“对齐税”)
ChatGPT(技术到产品)
RLHF(基于人类反馈的强化学习的指令微调)触发的能力:
l 翔实的回应
l 公正的回应
l 拒绝不当问题
l 拒绝其知识范围之外的问题
GPT-4v(听、说、看)
GPT-4可提供多模态能力:
l zero-shot及few-shot的能力
l GPT-4逻辑推理能力的飞跃
GPT-4的安全性已经大幅提升:
l 更强的专属能力(如编程)
l 处理其它语言的能力
l 处理更长序列的能力
GPT-4o(文科博士生)
l 多模态输入输出(交互能力)
l 响应速度(接近人类响应)
l 数学推理、编程等能力提升
l 非英文文本性能大幅提升
l 视觉和音频理解能力
l 成本优势
GPT-o1(理科博士生)
推理能力大幅提升:数学和编程能力爆表。
更像人类一样思考:全新安全训练方法 & 更强的“越狱”抵抗力。
04
DeepSeek
1.推理模型:从生成到推理的重心转变
OpenAl-o1/o3:推理能力的一大飞跃
DeepSeek-V3/R1:专家模型、强化学习,开源,效率
2.Deepseek模型并非是颠覆性基础理论创新
(Transformer-based),其对算法、模型和系统等进行的系统级协同工程创新,打破了大语言模型以大算力为核心的预期天花板,为受限资源下探索通用人工智能开辟了新的道路。
3.DS-V3对标GPT-40(文科博士生)
混合专家模型:V3基座模型总共有6710亿参数,但是每次token仅激活8个专家、370亿参数(~5.5%)
极致的工程优化:多头潜在注意力机制(MLA),使用FP8混合精度,DualPipe算法提升训练效率,将训练效率优化到极致,显存占用为其他模型的5%-13%
4.赋予DeepSeek-V3最基础的推理能力
R1-Zero使用DeepSeek-V3-Base作为基础模型,直接使用GRPO进行强化学习来提升模型的推理性能:
准确度奖励(Accuracyrewards)
格式奖励(Format rewards)
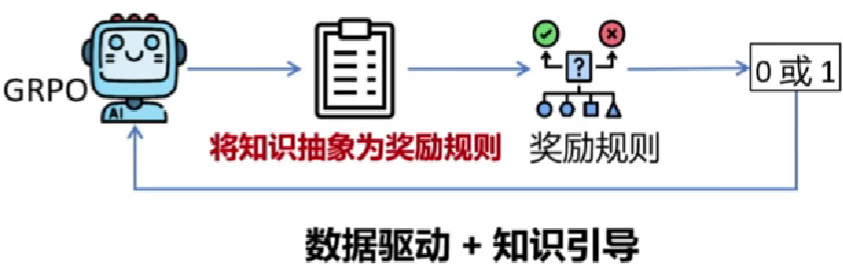
5.DS-R1对标OpenA1-01(理科博士生)
阶段1:DeepSeek-R1-Zero生成少量推理数据+SFT=>为V3植入初步推理能力(冷启动)。
阶段2:根据规则奖励直接进行强化学习(GRPO)训练=>提升推理能力(多轮迭代,获取大量推理数据)
阶段3:迭代生成推理/推理样本微调 =>增强全场景能力
阶段4:全场景强化学习 =>人类偏好对齐(RLHF)
6.DeepSeek-R1-Distill模型
(1)基于各个低参数量通用模型(千问、Llama等)
(2)使用DeepSeek-R1同款数据微调
(3)大幅提升低参数量模型性能
知识蒸馏:
老师教学生:“解题思路”,不仅给答案(硬标签),还教“为什么"(软标签)
模型瘦身:大幅压缩参数(如671亿→7亿参数),手机也能跑AI
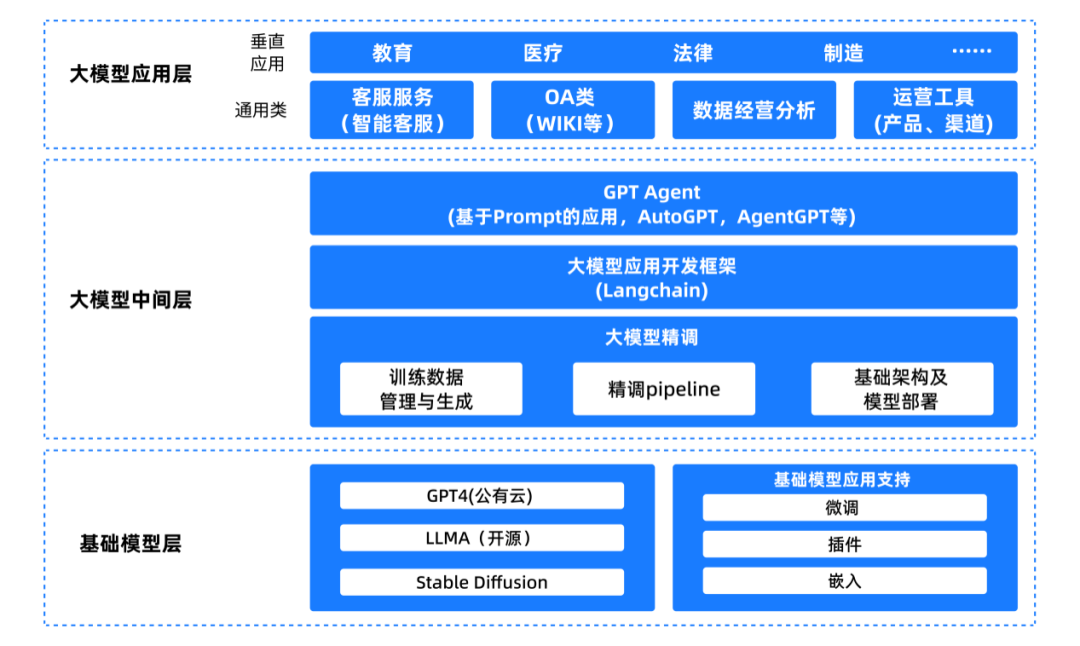
7.DeepSeek 带来的全栈影响
05
新一代智能体
新一代智能体=Agent + LLM
LLM是Agent的大脑,其核心能力是“逻辑推理”。
Planning skils:对问题进行拆解得到解决路径,既进行任务规划。
Tool Use:评估自己所需的工具,进行工具选择,并生成调用工具请求。
Memory:短期记忆包括工具返回值,已完成推理路径;长期记忆包括可访问的外部长期存储等。
公开课03
DeepSeek
智能金融:AI 驱动的金融变革
报告嘉宾:郑小林
浙江大学计算机学院教授、博士生导师,浙江大学计算机创新技术研究院副院长、人工智能研究所副所长,国家重点研发项目首席科学家。斯坦福大学访问学者,中国计算机学会杰出会员,IEEE资深会员,浙江省“万人计划”科技创新领军人才,浙江省151人才。
报告摘要
简单回顾大模型发展现状,提出人工智能面临的挑战,进而结合金融科技发展阶段对大模型的需求,提出可信金融大模型的思路,并结合智能营销、智能营销、智能投顾、智能监管等领域的研究实践和产业案例,为听众展示大模型在赋能金融科技中的核心竞争力。
01
新一代人工智能
AI的核心问题:建构能够跟人类似甚至超卓的推理、知识、计划、学习、交流、感知、移动移物、使用工具和操控机械的能力等。
自然语言处理模型的演进

新一代人工智能发展现状
02
金融智能研究
在金融市场中新一代人工智能面临的挑战
1.安全与隐私保护
模型窃取:通过未经授权的访问、泄露、复制等手段获取大模型权重、参数或训练数据
隐私泄露:利用模型记忆训练数据的特点,通过特定提问获取敏感信息
数据投毒:通过在训练数据中注入恶意样本误导模型学习,影响模型行为
对抗攻击:通过精心设计输入,绕过模型安全机制,使其生成危险或不适当的输出
2.算法共振
金融市场中多个决策模型因算法同质化、数据源相似或逻辑趋同,导致它们在市场中的交易行为高度同步,从而放大市场波动甚至引发系统性风险。
根因1:模型同质化
模型结构相似:依赖相似的基础模型(如LSTM、Transformer、强化学习)
数据来源相似:采用公开数据集进行训练
反应时机一致:信号到决策速度快,决策容易同步
根因2: 黑箱脆弱性
噪声数据敏感:深度学习模型对噪声数据的敏感性可能导致集体误判。
模型不可解释:决策逻辑缺乏透明,隐蔽未知风险容易叠加。
3.面临挑战3:创造力与幻觉率悖论?
DeepSeek R1 实测:推理增强后幻觉率增加。这可能是训练数据的奖励偏差,过度延展的推理机制导致的。
4.价值对齐
如何让大模型的能力和行为跟人类的价值、真实意图和伦理原则相一致,确保人类与人工智能协作过程中的安全与信任。这个问题被称为“价值对齐”或“人机对齐”(value alignment,或Al alignment)
金融智能:研究实践
1.市场前景广阔
金融大模型市场正快速扩张2023年,中国金融大模型市场的规模为15.93亿元:2024年上半年,市场规模已达到16亿元;2028年,预计将增长至131.79亿元。
中国金融大模型部署市场:MaaS部署(开箱即用、按需付费)占52%市场份额,引领中小型机构规模化应用,私有化部署占48%,是大型金融机构首选。
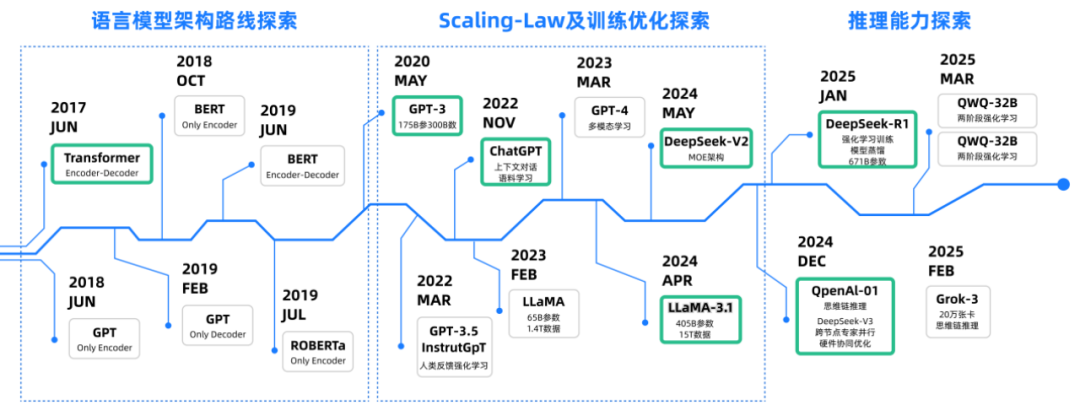
2.金融领域大模型
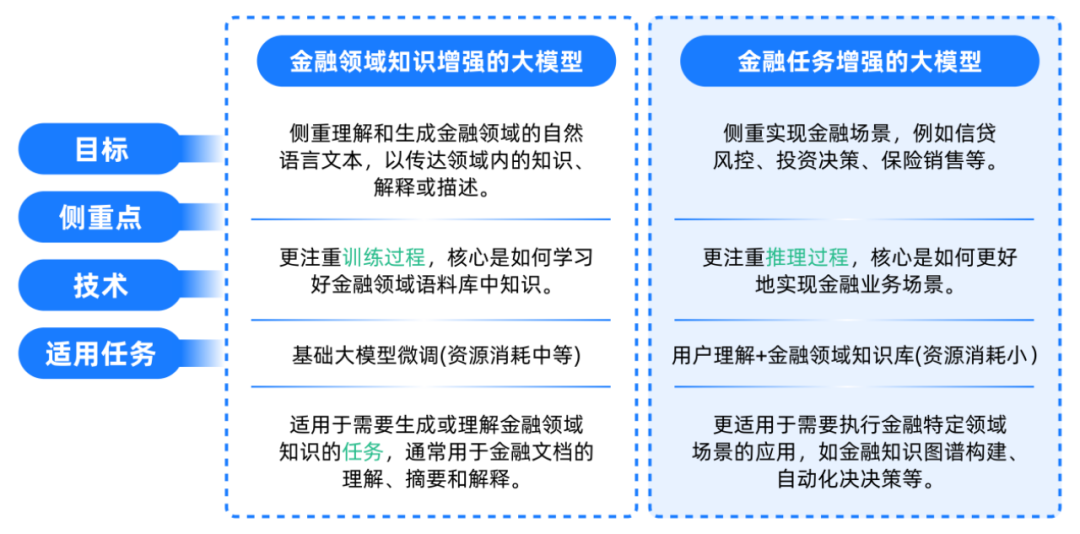
3.可信金融领域大模型研究框架
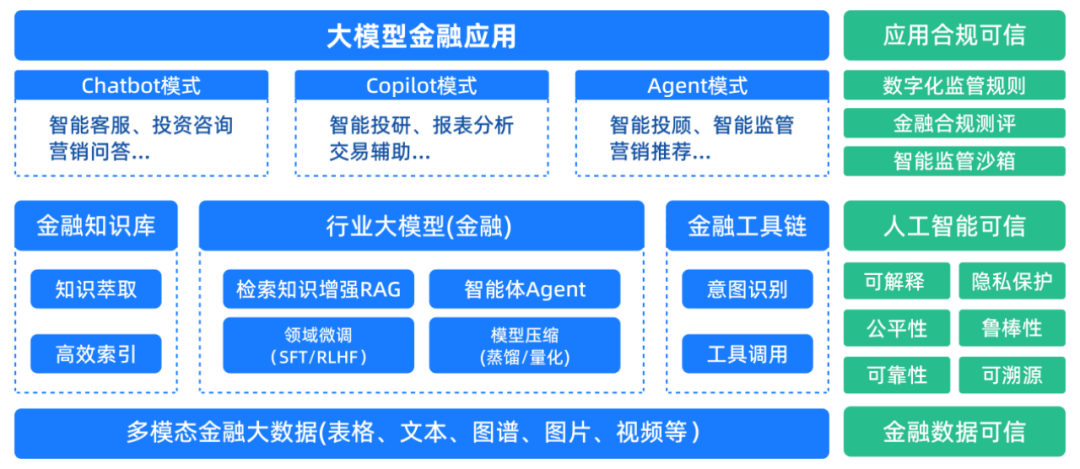
4.可信金融领域大模型研究框架-研究实践
基于模型设计开发了“智隐”内隐私计算平台,构建数据可用不可见、计算可信可链接、用途可控可计量平台,由可信金融领域大模型研究框架衍生的隐私保护大模型,联邦大模型(FedLLM)旨在保障隐私的同时整合多源数据,突破数据壁垒。
在营销领域,大模型项目围绕大模型在智能体(Agent)、检索增强生成(RAG)、模型微调三方面能力持续突破,解决“小鱼管家”金融营销应用中四大应用难题:建档回填繁琐、功能检索复杂、客群问答关联性差、产品问答不智能。
由此可见,金融领域的有效接入营销领域大模型项目围绕大模型在智能体(Agent)、检索增强生成(RAG)、模型微调三方面能力持续突破,解决“小鱼管家”金融营销应用中四大应用难题:建档回填繁琐、功能检索复杂、客群问答关联性差、产品问答不智能。是未来应用领域发展的趋势和前景,可信数据与可信模型相互促进,以LLM为中心的操作系统蓝图正在逐步形成过程当中。
 CpjJwWHV
CpjJwWHV
CpjJwWHV
CpjJwWHV







