


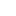

2025年,全球AI产业正经历一场空前的“算力饥渴症”。GPT-5 训练消耗的电力足以支撑一座百万人口城市运行一周,单次训练成本突破 5亿美元; Grok 3 的训练并非如此前传闻的在“10 万张 GPU 上进行”,而是使用了“20 万张 GPU”。对此,有网友指出其算力消耗是 DeepSeek V3 的 263 倍; 中国 DeepSeek-V3 训练数据量相当于GPT3的49倍。模型训练所使用的芯片主要是2000多块的NVIDIA H800 GPU组成的集群。
大模型密度定律仍未被被打破,伴随模型能力密度的指数级增强,算力需求会持续扩张。
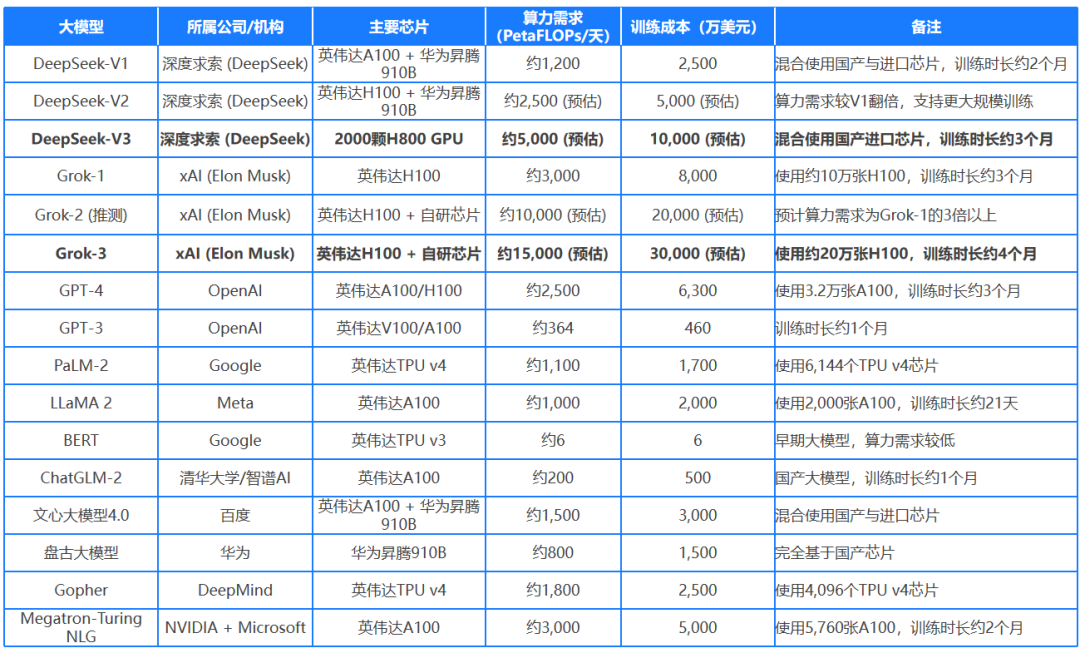
数据来源:浙大deepseek公开课第一季第二期;智云研报《2025年DeepSeek模型优势:算力、成本角度解读报告》;峰哥Python笔记《20万张GPU集群如何训练AI模型:DeepSeek、Grok3、GPT-4的成本、电力及基础设施解析》
何为算力?
算力并非是一个新兴的概念。从公元前就开始出现了依赖人工操作的非智能计算辅助工具,例如手指、结绳、算筹、算盘等。到达17世纪,人类进入了机械计算时代。帕斯卡计算器是1642年出现的首个机械加法器,它可以通过齿轮传动实现简单运算。
20世纪,人类是实现了从电子管计算机到超级计算机的飞速发展。计算机进入商用和科研领域,并可以为天气预报、核武器模拟等复杂科学计算提供支持。21世纪现代算力实现多维扩展,从分布式计算与云计算、 异构计算与专用芯片(CPU,TPU),到边缘计算与物联网。算力从人工到机械、电子、分布式再到智能化的演变,本质是人类突破自身生理与物理限制的过程。

算力与人工智能—"燃料"与"引擎"
AI性能 ≈ 算法效率 × 数据质量 × 算力规模
其中,算力是唯一可被量化的“硬指标”——它直接决定了模型训练的速度、规模与可能性。
算力的“摩尔定律困境”: 2012年,训练AlexNet(CNN鼻祖)仅需2块GPU,耗时5天;而2023年训练GPT-4需数万块A100芯片,耗电超50GWh(相当于一个小型城市年用电量)。算力需求每3-4个月翻一番,远超芯片制程迭代速度。
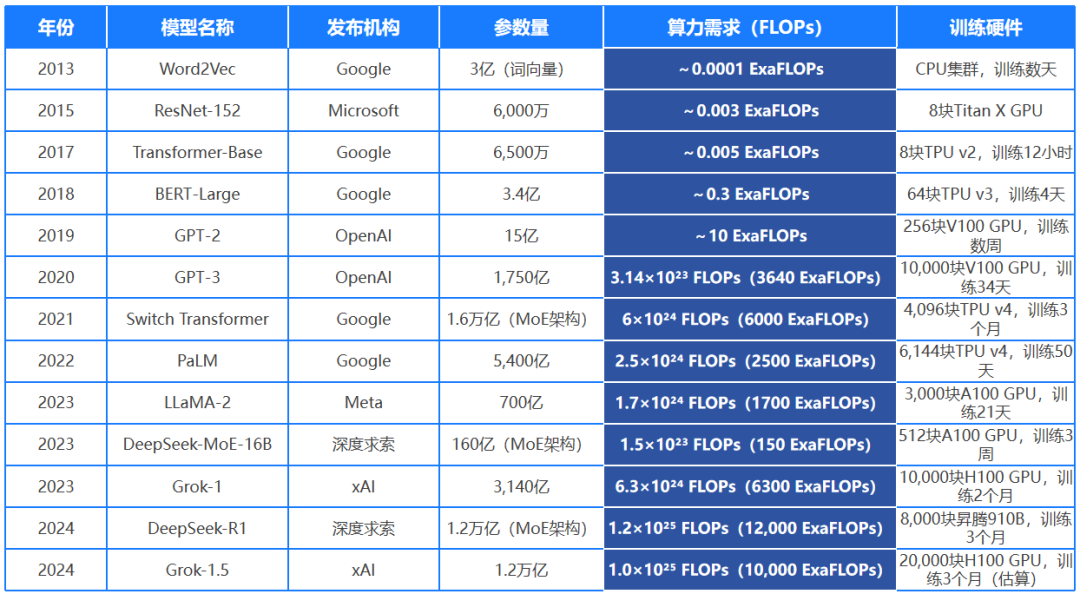

大模型所需算力变化
对中国的算力封锁
2022年10月,禁止A100/H100等高端GPU对华出口。
2023年10月,限制英伟达特供版A800/H800、AMD MI250,并将制裁延伸至云算力服务。
光刻机封锁,荷兰ASML被禁止向中国出售EUV及部分DUV光刻机,中芯国际14nm以下先进制程量产受阻。
芯片制造设备,应用材料、泛林等企业被限制对华出口刻蚀机、沉积设备。
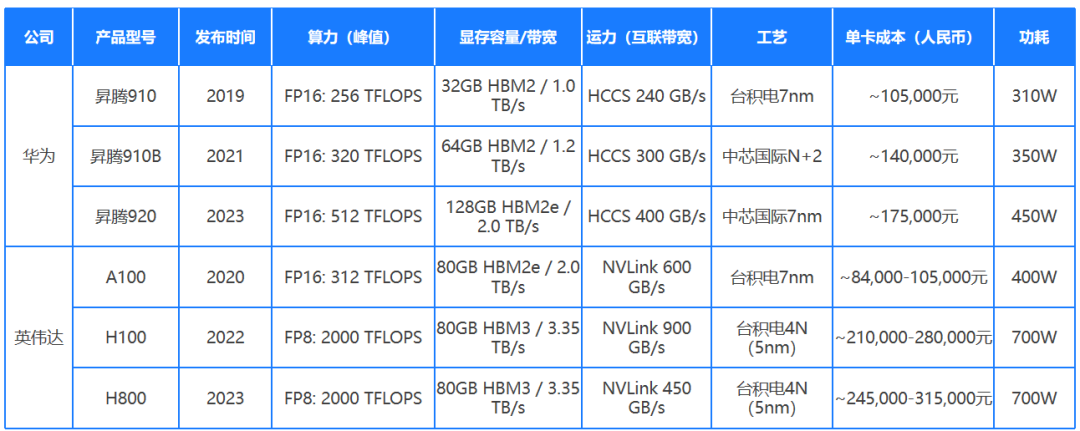
国内外主流算力能力对比
目前,AI大模型的竞争本质是算力的军备竞赛。然而国产芯片在工艺和生态上仍处劣势。
1.性能差距:单卡算力与互联技术落后
国外巨头:英伟达H100(FP16算力 2000 TFLOPS)、AMD MI300X(显存 192GB)等芯片,配合 NVLink高速互联技术(带宽900GB/s),可构建超大规模计算集群。
国内现状:华为昇腾910B(FP16算力 320 TFLOPS)、寒武纪思元590(显存64GB)等国产芯片,性能约为H100的15%-30%;互联技术多依赖PCIe 4.0(带宽64GB/s),集群效率仅为英伟达方案的30%-50%。
2.成本差距:单位算力价格翻倍
英伟达H100单卡售价约 3万美元,而国产芯片因制程(如14nm vs 台积电4nm)和生态劣势,单位算力成本高出2-3倍。若训练GPT-3级别模型,国内企业需多投入数千万美元。
云原生冲破算力封锁,AI时代的“弹性救星”
从前文的AI 模型训练的算力用量趋势图我们可以发现,算力需求呈现动态上升趋势。这说明算力并非是决定大模型成功与否的唯一标准。对现有算力调度提升与挖掘,是渡过目前中国算力封锁的重要方法,穷则战术穿插。
当芯片禁令撞上AI算力迫切需求,一场由代码驱动的算力解放运动正在中国云计算战场上悄然崛起。从DeepSeek首创动态计算流引擎(DCFE),提出5D混合并行框架等就证明了通过算法与生态将算力从物理约束中解放,为国产AI生态开辟了一条“以架构创新换制程差距”的突围路径的可行性和有效性。
而这种“以软制硬”的生态革命手段正是云原生的强项。云原生技术正以破局者的姿态,将"弹性基因"注入计算体系的毛细血管。云原生技术体系通过容器化、微服务编排和动态资源调度机制,为AI算力瓶颈问题提供了系统性的解决方案。
核心价值在于通过以下技术路径实现算力资源的高效利用:
1.基于Kubernetes的智能调度算法
可实时分析集群负载状态,在CPU/GPU异构计算环境中自动匹配最优任务分配策略,将AI训练任务分解至可用计算节点,使硬件资源利用率提升40%-65%。
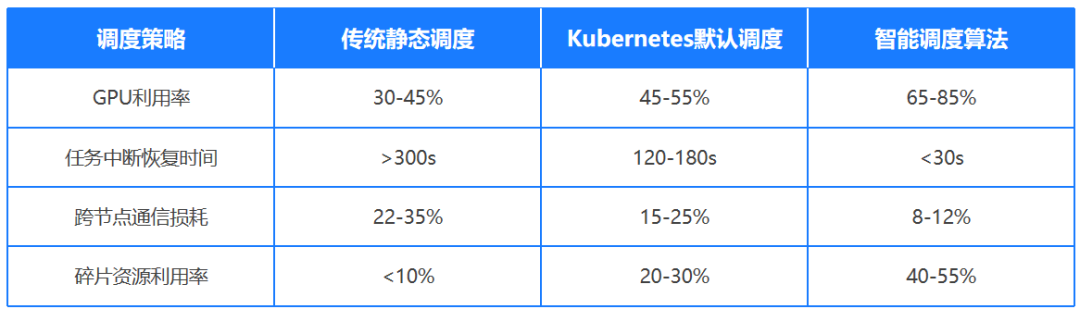
Volcano调度器优化LLM训练
字节跳动提出强化学习LLM Agent框架AGILE。在Kubernetes上扩展Volcano调度器,引入GANG调度算法解决大模型训练任务碎片化问题,开发DRF(Dominant Resource Fairness)策略实现GPU显存与计算单元的双维度调度。通过拓扑感知调度自动构建AllReduce通信环,将3500张A100显卡组成的集群利用率从58%提升至89%。
2.容器化混合部署
容器化的资源隔离特性支持混合部署场景,允许不同优先级、不同架构的AI工作负载共享物理资源,显著降低因资源碎片化导致的算力浪费。
NVIDIA DGX SuperPOD的异构架构混合部署
统一GPU池化:通过NVIDIA vGPU Manager将A100显卡分割为7个vGPU实例 架构无关封装:使用Singularity容器封装不同指令集的应用程序。DGX SuperPOD 混合部署可实现 80%+ GPU 利用率(传统场景通常低于 50%)。
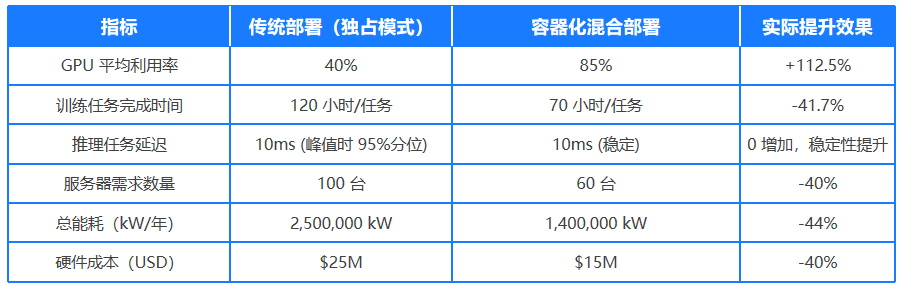
来源:NVIDIA 官方发布白皮书《Maximizing GPU Utilization with DGX SuperPOD》
阿里巴巴双11弹性资源池
双11期间流量峰值达日常的300倍,传统部署需提前数月扩容服务器,资源浪费率超50%。阿里巴巴双11采用容器化混合部署,基于Kubernetes(ACK)和自研Koordinator调度器,实现高优先级在线交易与低优先级离线任务(如数据分析)的动态资源调度。混部后集群CPU利用率从18%提升至75%,兼顾高弹性、低成本与业务零降级稳定性。(https://xie.infoq.cn/article/c2ed4baeeb632321766c5e912)
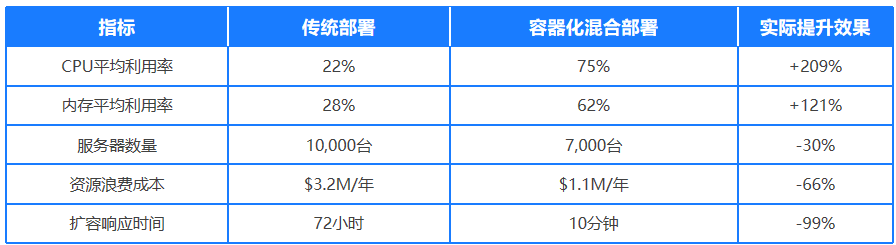
3.弹性伸缩机制结合细粒度监控指标
(如GPU显存占用率、张量计算单元利用率)可在毫秒级时间窗口内动态调整计算资源配置,有效应对AI模型训练中突发的大规模并行计算需求。
阿里云
LLM推理场景的潮汐流量特征,阿里云ACK集群结合Knative和Fluid技术实现。动态资源抢占:基于GPU利用率(监控粒度达毫秒级)和QPS指标,低峰时段释放50%GPU资源用于离线训练,高峰时段通过优先级策略抢占资源,整体资源闲置率下降60%。(来源:公众号阿里云基础设施)
4.资源池化效应
云原生架构的标准化接口设计打破了传统云计算平台的技术锁定,支持跨公有云、私有云及边缘节点的统一算力调度,形成分布式AI训练的资源池化效应。这些技术特性共同构建了面向AI工作负载的弹性计算基础设施,在硬件资源总量受限的情况下,通过提升单位算力产出效率来突破计算瓶颈。
多云资源统一纳管
火山引擎的分布式云原生平台(DCP)通过统一资源池化管理,支持跨AWS、阿里云、华为云等平台的GPU资源动态调度。其核心策略包括:智能分发:根据GPU型号、区域库存、成本优先级自动匹配最优资源;故障重调度:在单云资源不足时,自动切换至其他云或边缘节点;弹性伸缩:常驻资源与突发扩容资源的混合编排,降低闲置成本。
算力资源池化技术
趋动科技的猎户座OrionX通过GPU虚拟化技术,将物理GPU资源拆分为细粒度虚拟单元,实现跨服务器的共享调度。华为CloudMatrix进一步将CPU、NPU、内存等资源全互联池化,形成紧耦合的多元算力池,支持AI任务按需组合资源。此类技术可将GPU利用率从传统独占模式的30%提升至80%以上。
谐云算力管理平台
助力企业算力应用与管理
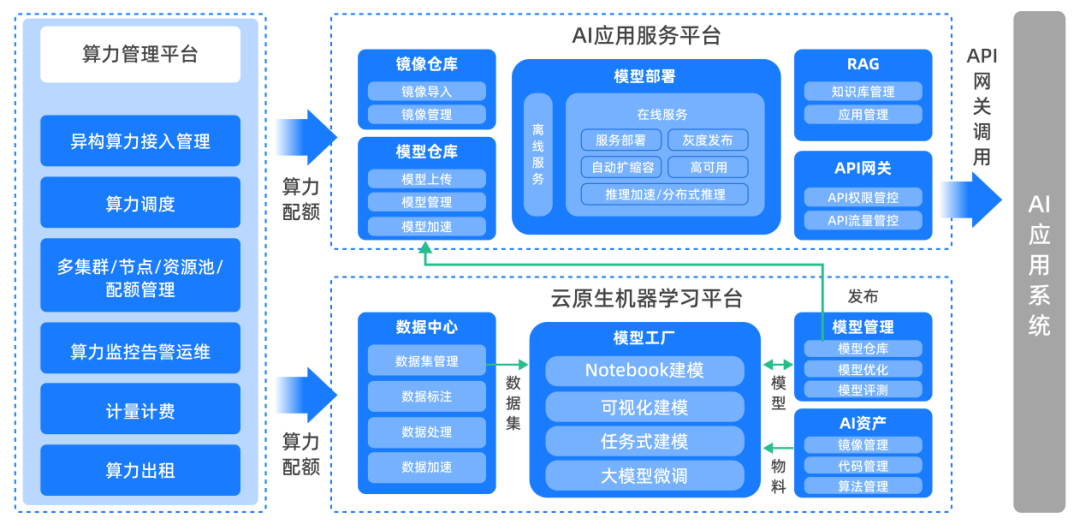
云原生的价值,在于用“软实力”弥补“硬差距”。
通过弹性调度、异构融合与算法创新,想象云原生技术能将国产芯片编织为全球效率顶尖的算力网络。通过跨平台资源池化、智能编排与软硬协同优化,云原生让每一焦耳能量迸发出超越物理硬件的智能密度。
 CpjJwWHV
CpjJwWHV
CpjJwWHV
CpjJwWHV







