



云原生技术的兴起,为AI的快速发展带来了前所未有的机遇和挑战。如何在云原生的加持下,让AI跑得更快、更稳、更智能,成为每个技术团队亟需解答的关键问题。从容器化部署到微服务架构,从弹性伸缩到智能调度,云原生为AI提供了更高效的运行环境和更灵活的资源管理方式。但随之而来的复杂性、性能瓶颈、安全风险等问题,也考验着技术团队的智慧与创新力。本文将深入探讨云原生时代AI加速升级的技术路径,解析如何打造更强大的AI基础设施,让AI在云端释放无限潜能。准备好迎接这场技术的变革了吗?
一、云原生如何赋能AI?
更快的开发与部署
在人工智能(AI)开发中,高效的基础设施和灵活的部署能力直接影响着项目的速度与效果。云原生技术通过容器化、微服务架构和自动化编排,为AI开发带来了革命性的变革,显著加速了从开发到部署的全流程。
首先,云原生的容器化技术(如Docker)为AI提供了标准化的开发环境,避免了“开发环境没问题,生产环境出问题”的尴尬。Kubernetes作为容器编排工具,进一步实现了资源的动态调度和高可用性,确保AI任务在异构算力(如GPU、NPU)上的高效运行。
例如国外Google提供的GCP平台的产品——CloudRun和GoogleKubernetes Engine(GKE)帮助AI抽象基础设施、协调工作负载,为AI工作负载提供开放、便携的解决方案。云原生技术通过标准化、自动化和弹性化,正在为AI开发与部署注入新的动力,帮助企业更快地将AI技术落地到业务场景中。(参考文献Estimating the Deployment Time for Cloud Applications using Novel Google Kubernetes Cloud Service over Microsoft Kubernetes Cloud Service)
更稳的运维与管理
在AI应用的管理中,运维的复杂性和不可控性常常成为企业落地的瓶颈。云原生技术通过自动化、弹性化和可观测性,显著简化了AI系统的运维与管理,提升了系统的稳定性和效率。
首先,云原生的核心工具Kubernetes为AI应用提供了自动化运维能力。Kubernetes的自动扩缩容(HPA)和故障自愈功能,能够根据负载动态调整资源,并在节点故障时快速恢复服务,确保AI系统的高可用性。例如,Uber利用Kubernetes管理其大规模的机器学习平台,显著减少了运维工作量,同时提升了系统弹性。
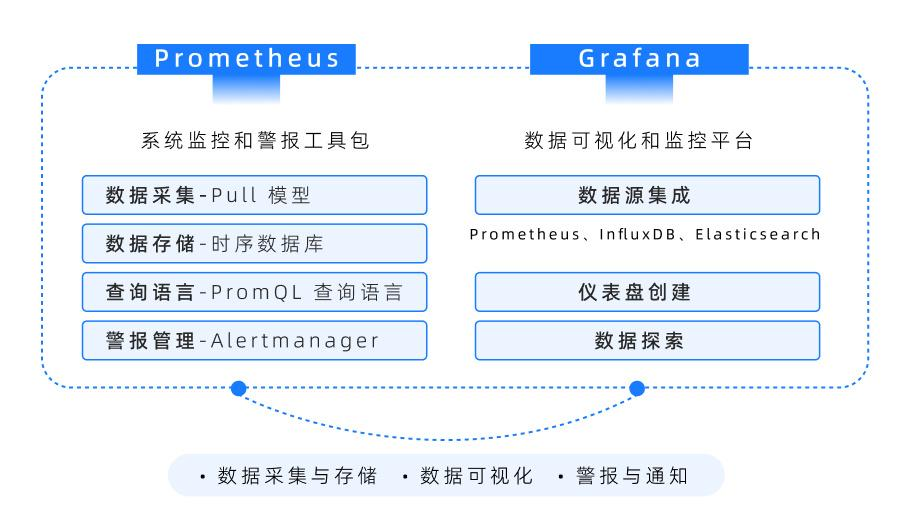
其次,云原生的可观测性工具(如Prometheus、Grafana监控与可视化的黄金组合)为AI运维提供了全面的监控和告警能力。通过实时监控模型服务的性能指标(如延迟、准确率),运维团队可以快速定位问题并采取行动。LinkedIn在AI推理服务中广泛使用了Prometheus,大幅降低了故障排查时间。
此外,云原生的GitOps实践通过版本控制和自动化部署,进一步降低了AI系统更新的复杂性。例如,Weaveworks通过GitOps实现了机器学习模型的自动化部署与回滚,提升了运维效率。
可见,云原生技术通过自动化、可观测性和一致性管理,为AI运维提供了强有力的支撑,帮助企业构建高效、稳定的人工智能系统。
更智能的优化与创新
云原生技术不仅革新了AI的开发与运维,还通过弹性资源调度、动态优化和高效创新环境,为AI的智能优化与创新提供了强大支持。
首先,云原生的弹性资源调度能力解决了AI任务中资源需求波动的问题。Kubernetes的动态资源分配和自动扩缩容(HPA)功能,可以根据模型训练或推理的负载,自动调整CPU、GPU等资源的使用。例如,OpenAI在训练大规模语言模型(如GPT系列)时,利用Kubernetes实现了分布式训练资源的动态优化,显著缩短了训练周期。
其次,云原生生态中的相关工具(如KubeflowKatib)提供了自动化超参数优化能力。通过智能搜索算法和分布式计算,快速找到最优模型配置。谷歌在优化视觉识别模型时,采用Katib进行超参数调优,使模型性能得到了广泛提升。自动化超参数优化对于帮助包括DeepSeek在内的大语言模型构建优化,缩短训练时间(高效搜索策略、并行化搜索等),提升模型性能(找到更优的超参数组合),优化资源利用率(动态资源分配),规模化与自动化(大规模搜索、端到端自动化),适应不同任务需求(多目标优化)有显著作用。
同时。为了满足对AI(人工智能)启发的HPC(高性能计算)/HPDA(高性能数据分析)工作负载的新兴需求,通过利用各种ML(机器学习)/DL(深度学习)工具和框架,包括SmartXAI在内的,由开源KubeFlow软件驱动的多功能AI集群已经迅速开发出来。(来源:Workflow Improvement for KubeFlow DL Performance over Cloud-Native SmartX AI Cluster)
此外,云原生为AI创新提供了高效实验平台。通过容器化和微服务架构,研究者可以快速构建、测试和迭代新算法。DeepMind在研发强化学习算法时,利用云原生环境实现了快速实验,加速了创新周期。
云原生技术通过资源优化、智能调优和创新支持,正在推动AI向更高效、更智能的方向发展,为技术突破和业务创新提供了强大动力。
二、架构:云原生AI的核心技术栈
算力底座:基于Kubernetes的集群管理
(官网http://kubernetes.io/)
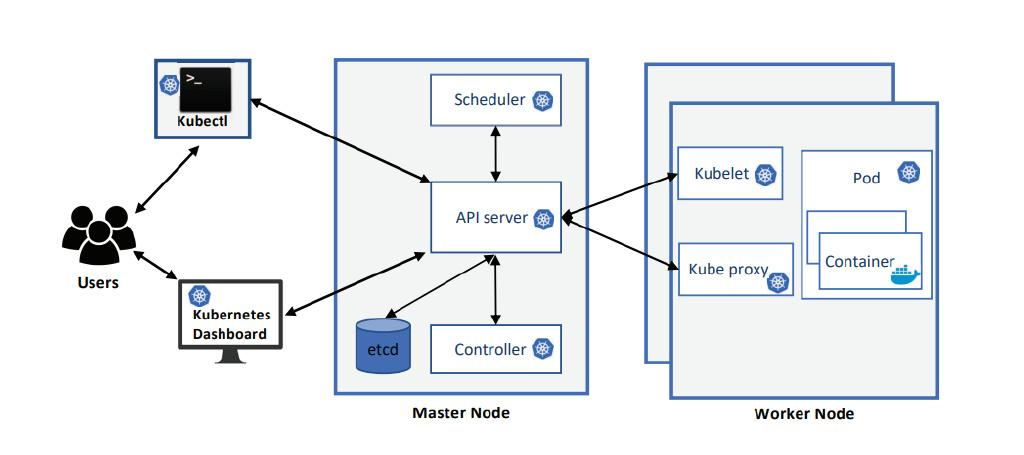
(Kubernetes概述/来源
XICommandmentsofKubernetesSecurity:ASystematizationofKnowledge RelatedtoKubernetesSecurityPractices)
Kubernetes在AI算力管理中的核心作用
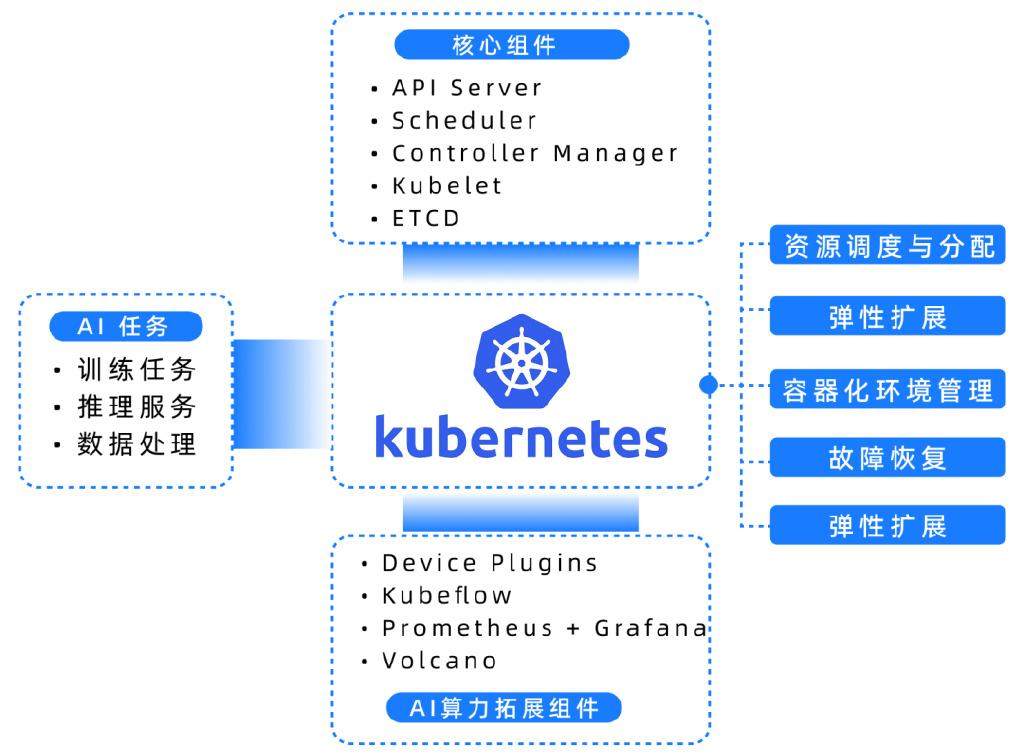
异构算力接入与调度
Kubernetes支持多种硬件资源的接入,包括CPU、GPU、NPU等,能够根据AI任务的需求自动分配算力。例如,在深度学习任务中,Kubernetes会自动将任务调度到GPU节点,加速模型训练。
资源动态伸缩
通过水平扩展(HorizontalPodAutoscaler),Kubernetes可以根据负载动态调整AI任的资源分配,确保高并发场景下的稳定运行。例如,当模型推理服务的请求量激增时,Kubernetes会自动增加Pod副本数,避免服务过载。
高可用与容错能力
Kubernetes提供了故障检测和自动恢复机制,确保AI任务在节点故障时快速迁移到其他节点,保障服务的连续性。例如,训练任务在某个节点中断时,Kubernetes会自动重新调度任务,避免数据丢失。
Kubernetes管理AI算力的优势
资源利用率最大化
Kubernetes通过资源共享和隔离机制,确保多个AI任务能够高效利用算力,减少资源浪费。
开发与运维的简化
Kubernetes的自动化能力(如部署、扩缩容、监控)大幅降低了AI开发的运维复杂度,让开发者更专注于算法创新。
跨平台一致性
Kubernetes支持混合云和多集群管理,企业可以在本地数据中心和公有云之间无缝迁移AI任务,实现跨平台的一致性。
开发平台:一站式AI工程化能力
一站式AI工程化平台核心功能模块
数据管理
功能:提供数据存储、清洗、预处理和版本管理能力,支持海量数据的快速处理。
优势:通过自动化的数据管道,减少人工干预,提高数据质量。
数据标注
功能:提供高效的标注工具,支持图像、文本、音视频等多种数据的标注。
优势:通过智能化标注(如预标注、自动标注)和多人协作,加速标注效率。
模型训练
功能:支持分布式训练、自动化超参优化和断点续训,加速模型收敛。
优势:通过算力调度和资源优化,提升训练效率,降低成本。
模型服务
功能:提供高可用、低延迟的模型部署和推理能力,支持在线和离线推理。
优势:通过自动扩缩容和监控告警,确保模型服务的稳定性和可扩展性。
一站式AI工程化平台的优势
全流程无缝衔接
从数据到模型的每一个环节都集成在同一个平台中,减少了跨工具、跨系统的切换成本。
开发的低门槛化
通过自动化工具和可视化界面,降低了AI开发的技术门槛,让普通开发者也能快速上手。
资源的高效利用
通过算力调度和资源共享机制,最大化利用硬件资源,降低开发成本。
运维的自动化
提供自动化的部署、监控和故障恢复能力,减少运维工作量,提升系统稳定性
三、为什么云原生是AI的最佳选择?
为什么云原生是AI的最佳选择?随着人工智能(AI)技术的快速发展,企业对高效、灵活且低成本的基础设施需求日益迫切。云原生技术凭借其独特的优势,正在成为AI开发与部署的最佳选择。
以下是云原生在AI领域的四大核心优势:
1.资源利用率最大化
AI任务(如模型训练和推理)通常对计算资源需求极高且波动性大。云原生技术通过容器化和Kubernetes的自动化资源调度,能够动态分配CPU、GPU等资源,确保资源利用最大化。
2.开发效率显著提升
云原生提供了标准化的开发环境,通过容器化技术和微服务架构,开发者可以快速构建、测试和部署AI模型。Google的AI平台结合Kubernetes,实现了大规模分布式训练的快速迭代,大大缩短了开发周期。
3.运维成本大幅降低
云原生通过自动化运维和故障自愈机制,显著降低了AI系统的运维复杂度。例如,Uber利用Kubernetes管理其机器学习平台,不仅提升了系统稳定性,还大幅减少了运维成本。
4.创新门槛显著降低
云原生的Serverless架构和GitOps实践让开发者无需关注底层基础设施,直接专注于模型创新。Weaveworks通过GitOps实现了机器学习模型的自动化部署与回滚,降低了创新门槛。
四、总结与展望
云原生技术通过容器化、微服务架构和自动化运维,为AI应用提供了高效、稳定且智能的基础设施。首先,Kubernetes的动态资源调度和自动扩缩容功能,让AI任务(如模型训练和推理)能够根据需求快速扩展,显著提升了计算效率。其次,云原生的可观测性工具(如Prometheus和Grafana)为AI系统提供了全面的监控与告警能力,确保系统稳定运行。此外,Serverless架构和GitOps实践降低了开发与运维的复杂性,让开发者更专注于模型优化与创新。
展望未来,随着云原生技术的不断成熟,AI将进一步提升性能与智能化水平。边缘计算与云原生的结合,将实现实时AI推理的普及;分布式训练优化工具(如Kubeflow)将继续推动大规模模型的训练效率;而自动化超参数调优技术将加速AI模型的优化迭代。
谐云创始团队来源于浙大,是国内最早进行云计算底层技术研究的团队,深耕云原生核心技术十余年,拥有全栈云原生产品与解决方案,并深度探索生成式AI、大模型等人工智能技术在云原生领域的融合应用,提供乾坤鼎云原生AI一体化平台、异构算力管理解决方案、大模型服务构建解决方案等一系列高性能云原生AI工程化平台与方案,助力企业数智化发展。
云原生不仅能让AI跑得更快、更稳,也为未来的智能创新打开了无限可能。








